di Gabriele Galati e Hellmut Riediger
Sembrano passati secoli, e invece era solo il 2003, quando Umberto Eco apriva il suo saggio sulla traduzione “Dire quasi la stessa cosa” con una selezione di esilaranti esempi dei risultati ottenuti con i traduttori automatici dell’epoca basati sulle regole. Pochi anni dopo Google con Translate, Microsoft e altri giganti del web diffusero su larga scala la traduzione automatica statistica: da semicomiche, le traduzioni automatiche, sebbene non perfette, cominciarono a diventare talvolta anche dei prodotti servibili, soprattutto se aggiustate attraverso opportuni interventi umani.
Nel 2011 il futurologo e cibernetico Ray Kurzweil in un’intervista al Huffington Post[1] arrivò a predire che dal 2029 la traduzione automatica sarà in grado di rimpiazzare gli esseri umani.
Ed ecco ora, dall’estate del 2016, è apparsa la traduzione automatica neurale.
Per molti rappresenta l’occasione, quasi escatologica, del definitivo abbattimento delle barriere linguistiche che dai tempi della maledizione babelica ostacolano i traffici, i commerci e la comprensione globale. Per altri, coloro che vivono della traduzione, l’avverarsi dell’incubo di una tecnologia che minaccia l’esistenza e la sussistenza di centinaia di migliaia di traduttori presenti e futuri.
Giordano Vintaloro, traduttore ed ex segretario del sindacato traduttori editoriali nel febbraio 2017 scrive che “le case editrici utilizzeranno a mani basse il nuovo Translate[2]” poiché “entro i prossimi tre anni il nuovo sistema di Google Translate basato sulle reti neurali sarà in grado di tradurre un intero romanzo in poche settimane[3] e … sarà inevitabile che molti traduttori a minore specializzazione (ma pur sempre laureati) si ritroveranno senza lavoro, e chiuderanno molti corsi di traduzione[4]”.
Addirittura la traduzione editoriale o letteraria che dir si voglia, viene dunque accostata alla traduzione automatica. E senza i soliti risolini di superiorità di quando tutti sostenevano che mai le macchine sarebbero state in grado di cogliere e interpretare ambiguità, connotazioni, sfumature, metafore o paradossi. Che sta succedendo?
I fatti
Il 26 settembre 2016, Google Brain, il gruppo di ricerca sulle applicazioni di intelligenza artificiale, ha annunciato il rilascio di un nuovo sistema di traduzione automatica basato sulle reti neurali[5]. Il 17 ottobre Systran ha fatto un annuncio analogo[6] e il 15 novembre il blog di Microsoft[7] ha informato che anche Microsoft Translator è ora disponibile in “versione neurale”. Nel maggio del 2017, infine, Facebook annuncia[8] di volere evolvere verso le reti neurali convoluzionali. Queste sarebbero nove volte più veloci nell’addestramento delle reti neurali ricorrenti introdotte invece quasi alla chetichella sulle piattaforme del gruppo Facebook, Instagram e Workplace dal giugno 2016. E intanto anche altri colossi informatici come Apple, Amazon e Baidu investono massicciamente nell’intelligenza artificiale.
Si afferma che questa tecnologia sarebbe in grado di produrre traduzioni molto più accurate e paragonabili alla traduzione umana.
Sembra che il lavoro del futuro, non solo quello dei traduttori, sarà gestito dall’intelligenza artificiale (grazie alla sua capacità di imparare da sé, cioè al cosiddetto machine learning) e da robot e applicazioni, con tutte le conseguenze economiche e sociali che ne derivano.
Le macchine stanno cominciando a “pensare” e sono destinate a sostituire il lavoro umano anche nelle attività considerate complesse.
Per esempio, Google e Tesla sono molto avanti nello sviluppo di auto senza conducente, che prefigurano una rivoluzione nella mobilità individuale. Ci saranno ancora i tassisti nel nostro prossimo futuro?
Cos’è l’intelligenza artificiale?
L’intelligenza artificiale è la disciplina che studia i modi di riprodurre i processi mentali più complessi mediante l’uso di computer. Per arrivare a questo si avvale di sistemi che prevedono l’acquisizione e l’elaborazione di dati e informazioni (sia provenienti dall’esterno, sia contenuti nel sistema in modo opportunamente organizzato) sulla base di opportuni modelli.
L’intelligenza artificiale oggi ha abbandonato l’idea della costruzione di un sistema precostituito di regole e dati, secondo la logica simbolica, per permettere alle macchine di interagire col mondo reale.
Attualmente i migliori risultati sono arrivati da sistemi che usano l’apprendimento automatico, in cui le macchine apprendono sul campo dai dati reali e orientano di conseguenza il loro funzionamento.
Deep learning è il termine con cui viene indicata una particolare classe di algoritmi per l’apprendimento automatico delle macchine, che usa le reti neurali.
Cosa sono le reti neurali?
Le reti neurali artificiali sono una tecnologia informatica, che imita le reti neuronali biologiche del sistema nervoso e del cervello umano: i nodi, unità di elaborazione semplici, tra loro fortemente interconnessi in una rete distribuita, organizzati per strati successivi, lavorano in parallelo su insiemi di dati. Esse non sono elementi programmati, ma sono strutture di dati statistici usate per costruire modelli dall’osservazione di dati, quando questi per la loro complessità risultano difficili da interpretare e da rappresentare con i normali strumenti dell’analisi manuale. Esse sono quindi usate per riconoscere schemi ricorrenti e modelli all’interno di grandi volumi di dati; classificarli e fare previsioni sulla base dei dati di input.
La caratteristica particolare di una rete neurale è quella di essere in grado di acquisire ”esperienza”, ovvero di auto-organizzarsi sulla base di esempi del compito che le viene richiesto. Si tratta pertanto di sistemi che, a differenza dei sistemi informatici statici, che si limitano ad assemblare dati in base a criteri statistici e di frequenza, si avvicinano molto alla logica umana.
Negli ultimi anni le reti neurali sono alla base dei notevoli progressi nell’ambito dei sistemi di riconoscimento vocale, di riconoscimento per immagini e per pattern, così come in quelli della biodiagnostica, del data mining, dell’anti-spam, dell’analisi finanziaria ecc.
Traduzione statistica e traduzione neurale: l’esempio di Google
I traduttori automatici di tipo statistico, come il “vecchio” Google Translate sono sistemi “Phrase-Based Machine Translation” che dispongono di database più o meno grandi di corrispondenze linguistiche da una lingua all’altra, a cui si aggiungono regole precaricate per ogni coppia linguistica.
Con questi sistemi una frase veniva tradotta per frammenti, locuzioni o gruppi di parole, trovati nei server di Google, all’interno di immensi corpora multilingue, in modo analogo a quanto si fa cercando nelle memorie di traduzione di un CAT tool.
Il risultato veniva poi riadattato dal sistema, interpolando la traduzione con dizionari e utilizzando modelli di interlingua per restituire la corretta costruzione della frase nelle varie lingue.
L’output è sempre stato di buon livello (vedi la nostra ricerca del 2013[9]): molto buono per varie lingue, ma sufficiente o scarso per alcune lingue (in particolare tedesco e finlandese, tra le lingue europee). Con variazioni a volte dovute alla punteggiatura, all’ordine delle parole e altro, che hanno originato una serie di raccomandazioni per il pre-editing del testo.
In ogni caso alla frase successiva, il processo partiva da capo e non teneva conto del risultato (buono o cattivo che fosse) della traduzione della precedente frase.
La particolarità delle reti neurali è la loro capacità di trasformare i dati da grandi insiemi non strutturati a insiemi più ridotti con un’alta densità semantica. Nella traduzione automatica neurale, il sistema, spiega Google, legge il testo originale parola per parola e parola per parola lo traduce, cercando di dare un peso alla distribuzione delle parole del testo originale lette e alla loro relazione con ogni parola tradotta.
Il sistema analizza cioè l’intera frase come un’unica unità da tradurre conservandone il contesto e riuscendo a tradurre anche sequenze con punteggiatura e articolazione grammaticale complessa, nonché paragrafi di senso compiuto.

Incremento della qualità della traduzione ottenuto con traduzione automatica neurale – Google
Il miglioramento dell’accuratezza della traduzione, secondo quanto osservato finora, è sorprendente ed è destinato, col tempo, a perfezionarsi con l’autoapprendimento (machine learning), al contrario dei sistemi precedenti, che erano sistemi chiusi.
Il sistema prende dunque in esame la frase nel suo insieme, ma non trascura i singoli elementi e tutte le loro accezioni. E dove la statistica dovesse risultare poco utile, per esempio nel caso di parole rare, il sistema è in grado di creare dei collegamenti e delle associazioni utili per il loro riconoscimento. Dal momento che si parla di autoapprendimento grazie a milioni di interazioni, verrebbe superato anche il problema dell’obsolescenza dei termini, poiché il sistema dovrebbe essere in grado di seguire le lingue nel loro sviluppo.
Google neurale, inoltre, fa a meno dei modelli interlingua[10] e applica la zero-shot translation, che prevede che non esista più una lingua pivot su cui girare la traduzione da una lingua per arrivare a un’altra, ma la relazione tra modelli simili: per esempio, se un testo è tradotto dall’inglese al coreano e al giapponese, il sistema fornisce la traduzione anche dal giapponese al coreano o viceversa, direttamente senza passare dall’inglese.
Le lingue disponibili in Google neurale
Le lingue inizialmente offerte sono state 8: oltre all’inglese, francese, tedesco, spagnolo, portoghese, cinese, giapponese, coreano e turco. Come ci ricorda Google, sono le lingue madri di un terzo della popolazione mondiale e coprono oltre il 35% di tutte le richieste di Google Translate.
Nel giro di poche settimane sono seguite russo, vietnamita, indonesiano e le nove più diffuse lingue indiane: hindi, bengali, marathi, gujarati, punjabi, tamil, telugu, malayalam e kannada.
La scelta delle lingue implementate è molto interessante, perché descrive implicitamente il valore commerciale di quelle aree geo-linguistiche del mondo.
A maggio 2017 Google ha introdotto la traduzione mediante reti neurali per 41 lingue, tra cui italiano – annunciano le mail di Google Community-
Tuttavia l’introduzione di nuove lingue di norma non viene dichiarata ufficialmente, lasciando scoprire da soli agli utenti i miglioramenti della traduzione. Così come nel settembre 2016 si è scelto di passare al nuovo sistema neurale, prima dell’annuncio ufficiale, lasciando agli utenti giudicare da soli la novità.
Fine della frammentazione babelica?
Dalla diffusione dei computer il lavoro si è sempre più trasformato in un lavoro di interazione con memorie digitali, prima CD-Rom, motori di ricerca, banche dati terminologiche, memorie di traduzione, traduzione automatica statistica. Ora questi grandi archivi digitali sembrerebbero mettersi in movimento da soli, riuscendo a fare a meno dell’apporto umano.
La fine della frammentazione babelica si sta avvicinando?
Talvolta uno sguardo alla storia aiuta a relativizzare il carattere apparentemente eccezionale di alcune situazioni del presente. Innanzi tutto va qui ricordato che sin dai suoi primordi alla fine degli anni ’40 per quanto riguarda la TA è stato un continuo oscillare tra grandi ed entusiastiche aspettative e forti disillusioni. Già con i primi rudimentali sistemi degli anni ’50, basati su vocabolari di qualche centinaio di parole e poche regole grammaticali molti pensarono che in tempi rapidi i traduttori automatici avrebbero potuto sostituire i traduttori umani. Un decennio dopo l’ottimismo si smorzò e negli Stati Uniti l’ALPAC (Automatic Language Processing Advisory Committee) in considerazione degli scarsi risultati raggiunti tagliò i fondi alla ricerca. Un’altra ondata di entusiasmo si ebbe negli anni ’90 quando furono sperimentati i primi sistemi statistici non più basati solo su regole, bensì su corpora di testi. I progressi apparvero incoraggianti, anche per testi più complessi. Quando questi sistemi poco dopo approdarono al Web, con i primi traduttori automatici online potevano attingere alla sempre crescente mole di testi disponibile in Rete. Tuttavia anche questa volta ci si rese conto che le cose miglioravano, ma che la totale automazione del processo e una buona qualità dell’output erano difficili per tutte le combinazioni linguistiche e per tutti i tipi di testi.
Oggi con la traduzione neurale, assistiamo dunque a un nuovo decollo delle aspettative, positive o negative a seconda dei punti di vista, anche in campo editoriale.
Sono più le domande che le risposte. Quanto tempo ci vorrà per vedere se il bambino di nome traduzione automatica neurale è effettivamente portato per la traduzione, e quale? Sarà usata soprattutto dal vasto pubblico, per la gioia del marketing, per traduzioni on the fly di contenuti web, post, email ecc? Riguarderà la traduzione professionale? Questa tende oggi a evitare, per motivi di riservatezza dei dati, i grandi traduttori automatici online , privilegiando applicazioni addestrabili alle proprie esigenze. Diventeranno neurali anche queste? Al momento non possiamo ancora esprimerci.
Intanto possiamo considerare la traduzione neurale una nuova tappa di una rivoluzione, avviata già da tempo dalla traduzione statistica. Una rivoluzione che riguarda la tecnologia, ma soprattutto anche il ruolo, l’uso e la funzione sociale della traduzione stessa.
Da anni, i sistemi di traduzione automatica, integrati ormai anche nei sistemi di traduzione assistita impiegati dai traduttori nella loro pratica professionale, e che ora minacciano di varcare le porte delle redazioni editoriali, sono già largamente usati da fornitori di servizi linguistici e servizi di traduzione di istituzioni pubbliche e private.
Già nel 2009 quasi il 50% degli operatori della traduzione (servizi linguistici e traduttori) dichiarava di far uso più o meno frequentemente di sistemi di traduzione automatica[11]. Nel 2014 il valore di mercato della TA è stato stimato pari a 250 milioni di dollari e il trend di crescita appare irreversibile (cfr. van der Meer 2014). Secondo un recente studio di Lommel e DePalma (2016)[12], le aziende tendono ad aumentare gli investimenti nella cosiddetta post-editing Machine Translation (PEMT) cioè l’uso della traduzione automatica per produrre una prima bozza della traduzione da correggere successivamente, ed entro il 2019 tradurranno o pretradurranno con la TA il 59% dei loro contenuti. Lommel e DiPalma (vedi tabella sotto) prevedono tra il 2016 e il 2019 un raddoppio del numero complessivo di parole tradotte con un raddoppio della parte tradotta in automatico (senza o con Post-editing), ma senza che questo significhi un calo della componente di traduzione umana, che, anzi, aumenterà anch’essa.
Il problema dunque non è tanto l’espulsione degli umani dal mondo della traduzione, semmai, quanto il livello delle tariffe che vengono pagate. Come in tutti i settori, si contrae il valore economico del lavoro umano. Grazie alla concorrenza al ribasso favorita dalla globalizzazione e da internet c’è sempre qualcuno che offre merci e servizi a prezzi inferiori, anche di traduzione.
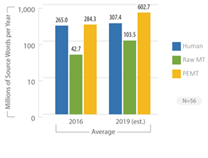
Il «peso» della TA nella traduzione professionale (Lommel e DiPalma 2016)
Ormai chi traduce a tempo pieno guadagna meno, soprattutto in ambito editoriale, della cifra ritenuta dignitosa per vivere in un Paese avanzato. Ma anche altre figure professionali non se la passano meglio. Si tratta di problemi senza dubbio legati all’evoluzione delle tecnologie ma in larga misura anche allo scarso peso negoziale di cui si dispone all’interno del contesto sociale e politico in cui viviamo.
Perché e a cosa serviranno ancora i traduttori umani?
L’automatizzazione della traduzione, di qualsiasi genere, renderà superflui i traduttori? Probabilmente no, o quanto meno non nel futuro prossimo. Tuttavia si svilupperanno nuove modalità e nuove prassi nella comunicazione interlinguistica che richiederanno nuove conoscenze e competenze che occorre apprendere…rapidamente. Proviamo ad elencarne qualcuna.
Ovviamente i traduttori dovranno possedere spiccate competenze tecnologiche. Dovranno possedere cultura, capacità di scrittura e approfondite conoscenze linguistiche e settoriali per essere in grado di valutare difficoltà e qualità dei testi. Dovranno essere in grado di gestire grandi quantità di testi in tempi circoscritti. Dovranno saper valutare se conviene tradurre automaticamente, valutare la quantità di post-editing, saper sottoporre un testo a pre-editing prima della sua traduzione, saper scrivere testi traducibili (scrittura controllata), saper addestrare i sistemi di TA o adattarli alle esigenze particolari. I traduttori diventeranno sempre più gestori di progetti di traduzione o di redazione multilingue. Un po’ redattori, editor, project manager, ma soprattutto sempre più revisori. Prima e dopo la stesura della traduzione, svolta dalla macchina. In fondo non si tratta di niente di completamente nuovo, ma ora diventa sempre più evidente. Già da qualche lustro, scrivere significa interagire con una varietà di tecnologie e memorie digitali (dizionari, glossari, banche dati, corpora, motori di ricerca ecc.). Poiché il principale effetto della rivoluzione tecnologica è stato l’enorme aumento delle nostre possibilità di memorizzare i dati, una parte sempre più cospicua dell’attività del traduttore consiste nella ricerca delle fonti (memorie) adatte prima della stesura e in varie forme di traduzione intralinguistica o adattamento (revisione, correzione di segmenti, post-editing ecc.) dopo la stesura. Pertanto da anni ormai il lavoro del traduttore consiste in larga misura nell’assemblare (copiare e incollare) frammenti recuperati da un qualche tipo di memoria digitale: porzioni di testo, espressioni o termini recuperati da propri precedenti lavori, dai risultati dei motori di ricerca, da dizionari elettronici, glossari, da banche dati terminologiche, da corpora paralleli reperiti in rete, da bitext, da memorie di traduzione oppure, appunto, da pretraduzioni fornite da sistemi di traduzione automatica. Il patchwork o «insalata di frasi» costituito dall’insieme dei segmenti e frammenti generati da un tale modo di lavorare devono poi essere sistemati in fase di post-traduzione o revisione, tendendo conto del grado di accuratezza richiesto.
La domanda che dunque si pone è: i programmi dei corsi di traduzione attuali aiutano a sviluppare queste competenze? Guardandosi un po’attorno, la risposta è che per i formatori dei futuri traduttori di lavoro da fare sicuramente ce n’è…
. ————————————
[1] http://www.huffingtonpost.com/nataly-kelly/ray-kurzweil-on-translati_b_875745.html
[2] https://www.rivistailmulino.it/news/newsitem/index/Item/News:NEWS_ITEM:3742
[3] https://www.tomshw.it/google-translate-sostituira-uomo-tradurre-romanzi-83577
[4] https://www.rivistailmulino.it/news/newsitem/index/Item/News:NEWS_ITEM:3742
[5] https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
[6] http://www.systransoft.com/download/press-releases/systran-pr-1st-software-provider-to-launch-a-neural-machine-translation-engine-in-more-than-30-languages-2016-10-17.pdf
[7] https://blogs.msdn.microsoft.com/translation/2016/11/15/microsoft-translator-launching-neural-network-based-translations-for-all-its-speech-languages/
[8] https://slator.com/technology/facebook-open-source-neural-machine-translation-zuckerberg-announces/
[9] http://www.fondazionemilano.eu/blogpress/weaver/pubblicazioni/
[10] http://www.geektime.com/2017/01/23/no-google-translate-did-not-invent-its-own-language-called-interlingua/
[11] https://workfortranslators.files.wordpress.com/2009/10/mygengo_state_of_translation_industry_2009.pdf
[12] http://www.commonsenseadvisory.com/AbstractView/tabid/74/ArticleID/36513/Title/MTsJourneytotheEnterprise/Default.aspx
Congrats, Gabriele e Hellmut, denso e grandioso post. Di sicuro lato formatori dei futuri traduttori non ci sarà da annoiarsi. Si dice che nel nostro settore la rivoluzione digitale stia registrando un autentico “salto quantico”, che i contenuti da tradurre stiano letteralmente esplodendo, che il mercato della localizzazione a livello globale sia ormai quantificato in ragione di 40 mld di USD, e che sia il 4° settore al mondo per crescita. Se poi consideriamo che ci si sono tuffati pure i mercati dei capitali (venture capitalist e private equity che fanno man bassa di LSP), e che le Big 5 dell’IT mondiale hanno cominciato a fornire servizi di MT (dopo Google, Microsoft e FB, ora sembra stia per arrivare anche Amazon), direi che l’attrattiva del nostro settore non ha bisogno di altri commenti. Last but not least, Google con Udacity ha appena confezionato un corso di introduzione alla localizzazione per far fronte alla carenza che afferma di riscontrare in termini di professionisti idonei per saturare la domanda globale di traduzioni. Insomma, rimbocchiamoci le maniche!
spero non si arrivi alla traduzione neurale artificiale perfetta al 100% (io per ora non la riscontro affatto), sarebbe la morte del mestiere di traduttore !
Non dimenticate anche: https://www.deepl.com/translator
migliore degli altri sistemi gratuiti.
Pingback: Traduttori senza tool e tool senza traduttori - L'IrrequietoL'Irrequieto
Il traduttore funziona in modo identico al traduttore Google del cellulare. La fregatura è che per far funzionare il traduttore enence ci serve obbligatoriamente il cellulare che fa da interfaccia ,perche ha bisogno di un collegamento internet da solo non serve a niente . Quindi evitate di spendere soldi .